



Table of contents


No headings in the article.
To implement, here's a quick overview of the IDENTITY property.
When most developers create primary keys. They do something like this:
CREATE TABLE Employees
(
Id INT PRIMARY KEY,
FirstName VARCHAR(100) NOT NULL,
LastName VARCHAR(100) NOT NULL,
);
Which works...
But let's see what happens when we start inserting records.
INSERT INTO Employees VALUES ('Ophelia', 'Barrera');
Oops, we run into an error, because we have to specify a primary key.
Ok, easy fix, let's just include some primary keys, so we can insert multiple rows.
INSERT INTO Employees
VALUES
(1, 'Ophelia', 'Barrera'),
(2, 'Glenda', 'Nicholson'),
(3, 'Tanner', 'Martinez'),
(4, 'Saul', 'Spencer');
It worked!
But, wait a minute...
We had to:
"Make up" primary keys
Specify them in our insert statement
This might not seem so bad because we're only inserting 4 records. But, what if we wanted to insert more? Say tens or hundreds?
Now, let's imagine if our table had thousands of records. We don't know what the primary keys are. For all we know, they could be random integers.
In order to insert the same records above, we would have to:
Query the table
Look for unused or "free" primary keys
Specify those primary keys in our insert statement
So, our insert statement could potentially look like this:
INSERT INTO Employees
VALUES
(111, 'Ophelia', 'Barrera'),
(122, 'Glenda', 'Nicholson'),
(200, 'Tanner', 'Martinez'),
(202, 'Saul', 'Spencer');
Now, imagine if we had to insert 100 records!
It should be rather obvious that this process could get quite cumbersome.
Thankfully, SQL Server offers an IDENTITY property.
We can make our Id column (INT PRIMARY KEY) an identity column, by providing two arguments:
a seed and;
an increment
And, what this does is allow the database to specify the values used in the Id column. The database computes this value using a very simple algorithm.
For the first value, it returns the seed
For each subsequent value, it returns the previous value plus the increment
So, now our table schema now looks like this.
CREATE TABLE Employees (
Id INT IDENTITY (1, 1) PRIMARY KEY,
FirstName VARCHAR(100) NOT NULL,
LastName VARCHAR(100) NOT NULL,
);
Our new insert statements are:
INSERT INTO Employees
VALUES
('Ophelia', 'Barrera'),
('Glenda', 'Nicholson'),
('Tanner', 'Martinez'),
('Saul', 'Spencer');
Notice, we don't need to specify the primary keys anymore.
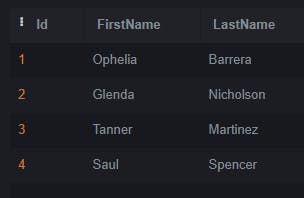
We can see the Id column of each row has been automatically populated. SQL server has kindly calculated those values for us.
This is wonderful.
This means, it doesn't matter how many records we insert, whether it's 100, 1,000 or even 1,000,000! The primary key will be populated for us, so we don't need to be concerned with primary keys at all.
Feel free to try it out for yourself.
The IDENTITY property is usually used on PRIMARY KEY columns, however that doesn't have to be the case.
You can use the IDENTITY property on any column of the following data type: tinyint, smallint, int, bigint, decimal, numeric.